线程基础 线程的创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> #include <thread> void func () std::cout << "hello world\n" ; } int main () std::thread t1 (func) ; t1.join (); return 0 ; }
如果函数需要传参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> #include <thread> void func (std::string name) std::cout << name << "\n" ; } int main () std::thread t1 (func , "127.0.0.1" ) ; t1.join (); return 0 ; }
仿函数作为参数
1 2 3 4 5 6 class Background_task {public : void operator [](const std::string& str) { std::cout << str << "\n" ; }; };
注意:
如果采用如下的方式调用函数,编译器一定会报错
1 2 std::thread t1 (Background_task()) ;t1.join ();
因为编译器会将t1当作一个函数对象,返回一个std::thread类型的值,函数的参数为一个函数指针,该函数指针返回值为Back_ground_task,参数为void
1 std::thread (*)(Background_task (*)());
修改的方式如下
1 2 3 4 std::thread t1 ((background_task())) ;t1.join (); std::thread t2{background_task ()}; t2.join ();
lambda表达式作为参数
1 2 3 4 5 std::thread t1 ([](const std::string& str){ std::cout << str << "\n" ; } , "hello world\n" ) t1.join ();
注意在线程中参数是以拷贝的形式进行传递,因此对于拷贝耗时的对象可以选择用引用或者指针进行传递。但是需要考虑对象的生命周期。因为线程的运行长度可能会超过参数的生命周期,这个时候如果线程还在访问一个已经被销毁的对象就会出现问题
detach 和 join
主要API
一旦启动线程之后,我们必须决定是要等待到这个线程结束(join),或者直接和主线程独立开来(detach),我们必须二者选其一。如果std::thread对象销毁时我们还没有触发任何操作,则std::thread对象在析构函数将调用std::terminate()从而导致进程异常退出
对于这两个接口,都必须是可执行的线程才有意义。可以通过joinable()接口查询是否可以对它们进行join或者detach
管理线程
yield: 通常在自己的主要任务已经完成时,希望让出处理器给其他任务使用
get_id: 返回当前线程的id,可以用来标识不同的线程
sleep_for: 可以让当前线程停滞一段时间
sleep_until: 和sleep_for类似,但是以具体时间点为参数,这两个API都是以chronoapi为基础
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iomanip> #include <iostream> #include <thread> #include <sstream> void print_time () auto now = std::chrono::system_clock::now (); auto in_time_t = std::chrono::system_clock::to_time_t (now); std::stringstream ssin; ssin << std::put_time (std::localtime (&in_time_t ) , "%Y-%m-%d %X" ); std::cout << "now is: " << ssin.str () << "\n" ; } void sleep_thread () std::this_thread::sleep_for (std::chrono::seconds (3 )); std::cout << "[thread-" << std::this_thread::get_id () << "] is waking up\n" ; } void loop_thread () for (int i = 0 ; i < 10 ; i++) { std::cout << "[thread-" << std::this_thread::get_id () << "] print: " << i << "\n" ; } } int main () print_time (); std::thread t1 (sleep_thread) , t2 (loop_thread) ; t1.join (); t2.detach (); print_time (); return 0 ; }
线程的归属权
每个线程都有其归属权,也就是说归属给每个变量管理
1 2 3 4 5 6 7 void func () } std::thread t1 (func) ;
t1是一个线程变量,管理一个线程,该线程执行func()对于std::threadC++不允许拷贝构造和拷贝赋值,所以只能通过移动和局部变量返回的方式将线程变量管理权转移给其他变量管理。
例如下面的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <thread> #include <chrono> namespace {void func1 () while (true ) { std::this_thread::sleep_for (std::chrono::seconds (1 )); } } void func2 () while (true ) { std::this_thread::sleep_for (std::chrono::seconds (1 )); } } }; int main () std::thread t1 (func1) ; std::thread t2 = std::move (t1); t1 = std::thread (func2); std::thread t3; t3 = std::move (t2); t1 = std::move (t3); std::this_thread::sleep_for (std::chrono::seconds (2000 )); return 0 ; }
异常处理 当我们启动一个线程之后,如果主线程崩溃,会导致子线程也会异常退出,调用std::terminate(),如果自线程在进行一些重要的操作比如将充值信息入库等,丢失这些信息是很为危险的。所以常用的做法是捕获异常,并且在异常情况下保证子线程稳定运行结束后,主线程抛出异常结束运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void catch_exception () int some_local_state = 0 ; std::function<void ()> myfunc = [](){ }; std::thread functhread (myfunc) ; try { std::this_thread::sleep_for (std::chrono::seconds (1 )); } catch (std::exception& e) { functhread.join (); throw std::runtime_error ("ababababa\n" ); } functhread.join (); }
但是用这种方式编码会显得臃肿,可以使用RAII技术,保证线程对象析构的时候等待线程运行结束,回收资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class thread_guard {private : std::thread& _t ; public : explicit thread_guard (std::thread& t) : _t(t) { ~thread_guard () { if (_t .joinable ()) { _t .join (); } } thread_guard (const thread_guard&) = delete ; thread_guard& operator =(const thread_guard&) = delete ; }; void auto_guard () int some_local_state = 0 ; std::function<void ()> myfunc = [](){ }; std::thread t1 (myfunc) ; thread_guard guard (t1) ; std::cout << "auto guard finish\n" ; }
慎用隐式转换 C++中会有一些隐式转换,例如char*转换为std::string等,这些隐式转换在线程的调用上可能会造成崩溃问题
1 2 3 4 5 6 7 8 9 10 void danger_oops (int som_param) char buffer[1024 ]; sprintf (buffer, "%i" , som_param); std::thread t (print_str, 3 , buffer) ; t.detach (); std::cout << "danger oops finished " << std::endl; }
在以上代码中,当我们定义一个线程变量thread t时,传递给这个线程参数buffer会被保存到thread的成员变量中。而在线程对象t内部启动并运行线程时,参数才会被传递给调用函数print_str。而此时buffer可能到}就被销毁了。改进方式很简单,我们将参数传递给thread时显示转换成string就可以了,其实相当于拷贝一份过去。
1 2 3 4 5 6 7 8 9 10 11 void danger_oops (int som_param) char buffer[1024 ]; sprintf (buffer, "%i" , som_param); std::thread t (print_str, 3 , std::string(buffer)) ; t.detach (); std::cout << "danger oops finished " << std::endl; }
引用参数 在线程要调用的回调函数参数作为引用类型时,需要将参数显式转换为引用对象传递给构造函数,如果采用如下调用会编译失败
1 2 3 4 5 6 7 8 9 10 11 void change_param (int & param) ++param; } void ref_oops (int some_param) std::cout << "before change , param is " << some_param << std::endl; std::thread t2 (change_param , some_param) ; t2.join (); std::cout << "after change , param is " << some_param << std::endl; }
即使函数change_param的参数为int&类型,我们传递给t2的构造函数为some_param,也不会达到在change_param函数内部修改关联到外部some_param的效果。因为some_param在传递给thread的构造函数后会转变为右值保存,右值传递给一个左值引用会出问题,所以编译也出了问题。
只需要使用std::ref()就可以解决
1 2 3 4 5 6 7 8 9 10 11 12 13 void change_param (int & param) ++param; } void ref_oops (int some_param) std::cout << "before change , param is " << some_param << std::endl; std::thread t2 (change_param , std::ref(some_param)) ; t2.join (); std::cout << "after change , param is " << some_param << std::endl; }
绑定类成员函数 有时候我们需要绑定一个类的成员函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 class X {public : void do_length_work () std::cout << "do_length_work" << std::endl; } }; void bind_class_oops () X my_x; std::thread t (&X::do_length_work , &my_x) ; t.join (); }
注意,如果thread绑定的是普通函数,可以在函数前加&或者不加&,因为编译器默认将普通函数名作为函数地址,但是如果是绑定类的成员函数,必须加&
1 2 3 4 5 6 7 void thead_work1 (std::string str) std::cout << "str is " << str << std::endl; } std::string hellostr = "hello world!" ; std::thread t1 (thead_work1, hellostr) ;std::thread t2 (&thead_work1, hellostr) ;
使用move操作 有时候传递给线程的参数是独占的,所谓独占就是不支持拷贝赋值和构造,但是我们可以通过std::move()的方式将参数的所有权转移给线程。
1 2 3 4 5 6 7 8 9 10 11 12 void deal_unqiue (std::unique_ptr<int > p) std::cout << "unique ptr data is " << *p << std::endl; (*p)++; std::cout << "after unqiue ptr data is " << *p << std::endl; } void move_oops () auto p = std::make_unique <int >(100 ); std::thread t (deal_unqiue , std::move(p)) ; t.join (); }
一次调用 在一些情况下,我们有些任务需要执行一次,并且我们只希望它执行一次,例如资源的初始化人物。这个时候就可以用到std::call_once和std::once_flag。这两个接口保证即便在多线程的环境下,相应的函数也只会调用一次。
例如下面的代码,有四个线程会执行init()函数,但是只有一个线程会执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <thread> #include <mutex> void init () std::cout << "Initializing...." << std::endl; } void worker (std::once_flag& flag) std::call_once (flag, init); } int main () std::once_flag flag; std::thread t1 ( worker, std::ref(flag) ) ; std::thread t2 ( worker, std::ref(flag) ) ; std::thread t3 ( worker, std::ref(flag) ) ; std::thread t4 ( worker, std::ref(flag) ) ; std::thread t5 ( worker, std::ref(flag) ) ; t1.join (); t2.join (); t3.join (); t4.join (); t5.join (); return 0 ; }
注意,我们无法确定哪个线程执行了init()函数,但是我们也不需要关心,因为只要有一个线程执行了init()函数就可以了
并发任务 实例:需要计算某个范围内所有数的平方根总和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <thread> #include <mutex> #include <cmath> #include <chrono> static int MAX = 10e8 ;static double sum = 0 ;void func (int min , int max) for (int i = min ; i <= max; i++) { sum += sqrt (i); } } void task (int min , int max) auto start_time = std::chrono::steady_clock::now (); sum = 0 ; func (min , max); auto end_time = std::chrono::steady_clock::now (); auto ms = std::chrono::duration_cast <std::chrono::milliseconds>(end_time - start_time).count (); std::cout << "Task finish, " << ms << " ms consumed , Result: " << sum << "\n" ; } int main () task (1 , MAX); return 0 ; }
输出为
1 Task finish, 1821 ms consumed , Result: 2.10819e+13
很明显上面的计算使用单线程性能太差,可以使用并发进行。
先获取当前硬件支持多少个线程并行执行
根据处理器情况决定线程数量
对于每一个线程都通过func()函数来完成任务,并划分一部分数据给它处理
等待每一个线程结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void concurrent_task (int min , int max) auto start_time = std::chrono::steady_clock::nowxainshi (); unsigned int concurrent_count = std::thread::hardware_concurrency (); std::cout << "hardware_concurrency: " << concurrent_count << "\n" ; std::vector<std::thread> threads; min = 0 ; sum = 0 ; for (int t = 0 ; t < concurrent_count; t++) { int range = max / concurrent_count * (t + 1 ); threads.push_back (std::thread (func , min , range)); min = range + 1 ; } for (auto &i : threads) { i.join (); } auto end_time = std::chrono::steady_clock::now (); auto ms = std::chrono::duration_cast <std::chrono::milliseconds>(end_time - start_time).count (); std::cout << "Task finish, " << ms << " ms consumed , Result: " << sum << "\n" ; }
输出如下
1 2 hardware_concurrency: 20 Task finish, 2086 ms consumed , Result: 1.53287e+12
但是我们会发现性能并没有多少提升,并且结果还是错的。
要搞清楚为什么,我们需要一点背景知识
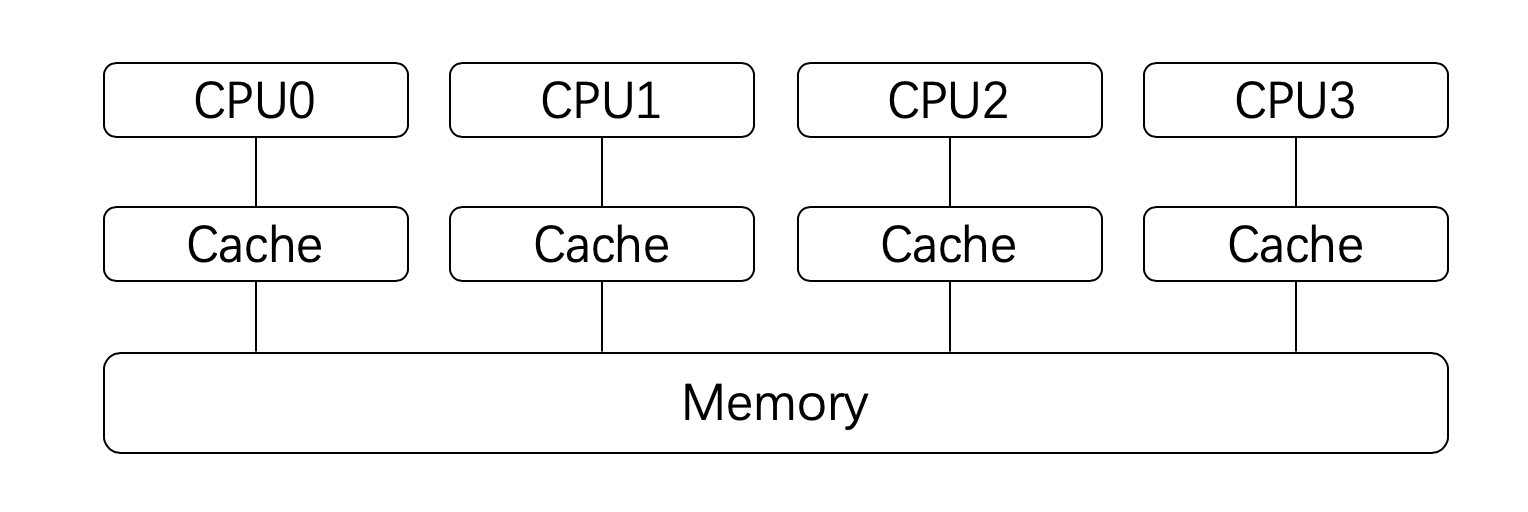
对于现代处理器来说,为了加速处理的速度,每个处理器都会有自己的高速缓存,这个高速缓存是与每个处理相对应的
现在的处理器起码有三级缓存
处理器在进行计算的时候,高速缓存会参与其中,例如数据的读和写。而高速缓存和系统主存(Memory)是有可能存在不一致的。即:某个结果计算后保存在处理器的高速缓存中了,但是没有同步到主存中,此时这个值对于其他处理器就是不可见的。
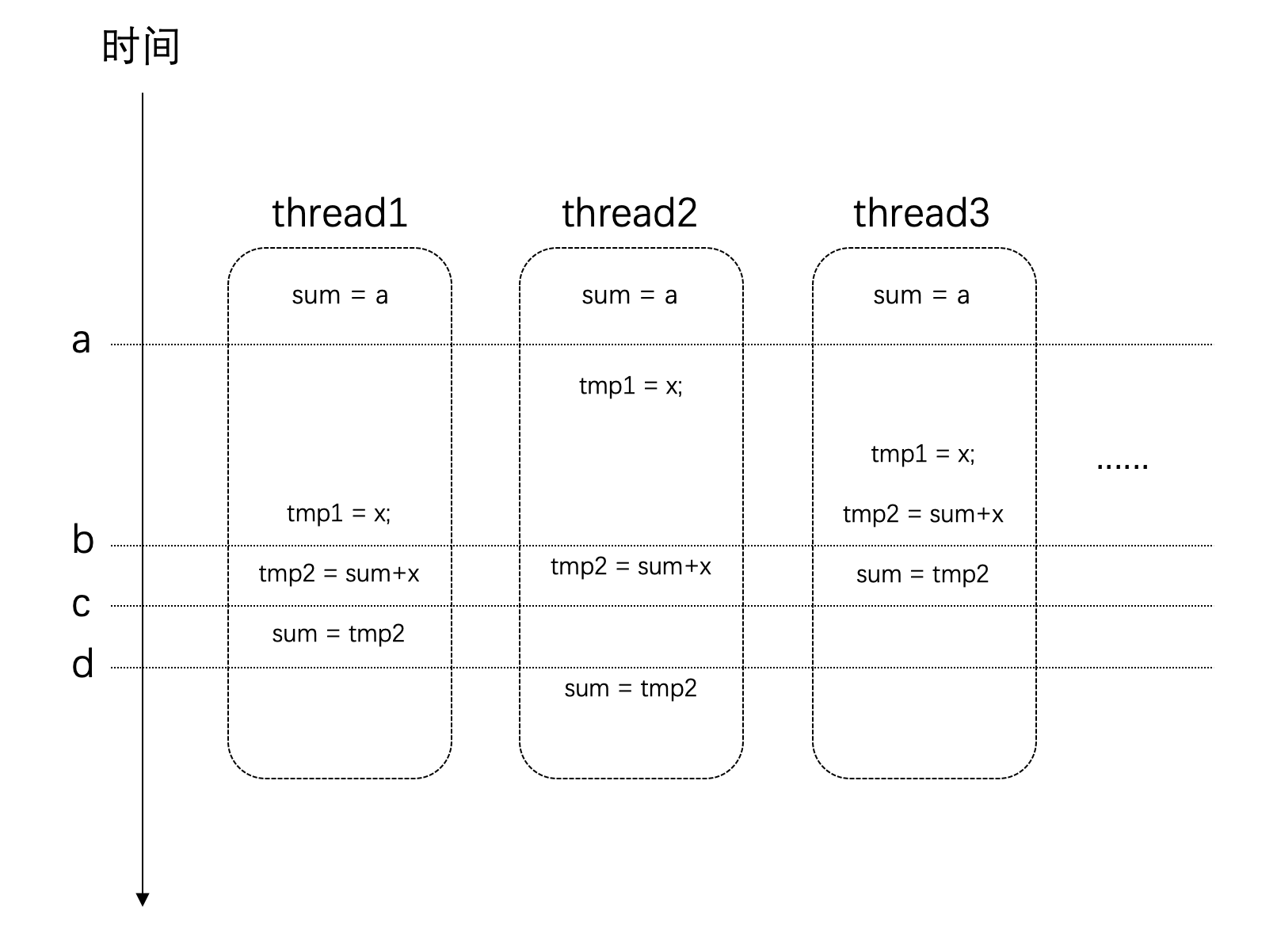
事情还没有这么简单。我们对于全局变量值的修改sum += sqrt(i);这条语句,它并非是原子的。它其实很多条指令的组合才完成的。假设在某个设备上,这条语句通过下面这几个步骤来完成的,时序可能如下:
如图所示,在时间点a的时候,所有线程对于sum变量的值是一致的。
但是在时间点b之后,thread3上已经对sum进行了赋值,而这个时候其他几个线程也同时在其他处理器上使用了这个值,那么这个时候它们所使用的值是旧的,也就是错误的。最后得到的结果也就是错误的。
竞争条件与临界区 当多个进程或者线程同时访问共享数据时,只要有一个任务会修改数据,那么就可能会发生问题。此时结果依赖于这些任务执行的相对时间,这种场景称为竞争条件
访问共享数据的代码片段称之为临界区 。例如上面的实例,临界区就是读写sum变量的地方
要避免竞争条件,就需要对临界区进行数据保护。
那么对于上面的实例的解决方法就是一次只让一个线程访问共享数据,访问完了再让其他线程接着访问,这样就可以避免问题发生了。